Strings and encodings in Qt
This is a short introduction to encodings, and how not to fail at using them inside Qt (and in general inside a C/C++ project).
IMPORTANT NOTE
The contents of this page need updating to Qt 5. Qt 5 makes more use of UTF-8. In doubt, always consult the manual.
The short recipe
- There Ain't No Such Thing As Plain Text.
- Encode your source code files using UTF-8. Set all your tools (editors, etc.) to read and write UTF-8 files. Do it once, for all your code base, and make your colleagues stick with it.
- Make your compiler read UTF-8 files. Changing your locale to an UTF-8 locale should be enough (otherwise, see your compiler's manual).
- In your code use QStringLiteral / QString::fromUtf8() for all string literals, and tr() (in Qt 4: trUtf8() / QT_TR_UTF8() / etc.) for all user-visible strings.
- If you really want to use the QString(const char *) constructor[1], in Qt 4, remember to call QTextCodec::setCodecForCStrings() passing the UTF-8 text codec (QTextCodec::codecForName("UTF-8")). Being an application wide setting, this might break plugins or 3rd party Qt libraries. Note that in Qt 5 this constructor expects a UTF-8 string already.
The long story
Encodings in C/C++
What is the encoding of string literals in C/C+?
The C and C+ specifications don't say much about the encoding of string literals inside a program — or about the encoding of a program's source code itself. They just specify that an input character set and an execution character set do exist, with some simple requirements.
So what?
A compiler has to employ several techniques to deal with this problem. For starters, it must properly decode the bytes of the source file into a C/C++ program (so that the parser can parse the program). This is usually done using the current locale settings, or falling back to UTF-8 (it's ASCII compatible); if you are using GCC you can pass the -finput-charset= command line option to specify a certain encoding for the input files.
And then?
Once a source file is parsed, the compiler keeps the string literals in an internal, private representation, which is not really interesting — as compiler users, it suffices for us that this internal representation is able to represent any possible symbol in any alphabet. This usually means that this internal representation is actually a Unicode encoding.
In the end, the compiler has to emit some assembly code for the strings, that is, sequences of raw bytes; therefore, it has to encode the strings using an execution encoding. Again, if you're using GCC you can pass the -fexec-charset= and -fwide-exec-charset= command line options to control which encoding is used for the char[] literals and the wchar_t[] literals respectively (by default they're UTF-8 and UTF-16 or UTF-32, depending on the size of wchar_t).[2]
What's the scope of such command line options?
The invocation of the compiler in which they appear, so one translation unit — yes, you can change the input and execution charsets for every translation unit, if you want.
Wait a minute… so what does o exactly?
The escape sequence inside a string literal encodes the code point U+XXXX using the execution character set (similarly, the encodes the code point U+XXXXXXXX). Note that s, in general, a prefix for an universal character, and you're allowed to use it even outside string literals.
How does Qt know the encoding of a byte array (a char *), for instance, when I build a QString from it?
It's simple: Qt doesn't know it. For instance:
- the QString(const char *) constructor in Qt 5 expects UTF-8 and UTF-8 only. In Qt 4, it uses the QTextCodec::codecForCStrings() if one was set, or falls back to Latin-1 — so if you pass data in any other encoding, including UTF-8, it may horribly break;
- the static QString::fromLatin1() method builds a string from Latin-1 encoded data;
- the static QString::fromUtf8() method builds a string from UTF-8 encoded data;
- the tr() method for translation expects UTF-8 in Qt 5 (in Qt 4 the QTextCodec::codecForTr() if one was set, or, again, falls back to Latin-1);
- in Qt 4 the lupdate tool uses the CODECFORTR and CODECFORSRC in your .pro file to know the encoding of the strings inside tr() and of your source files;
- for any other encoding schemes you have to build a proper QTextCodec (by using QTextCodec::codecForName() or similar methods), and then use its toUnicode() method.
QString
What's QString?
QString is a re-entrant, implicitly shared container for an UTF-16 encoded string. This means (in no particular order):
- All methods that take an index, as well as the iterators, work in terms of code units, not code points.
- A QString might contain invalid data (for instance a broken surrogate pair).
- …
But what's wrong with the QString(const char *) constructor?
In Qt 4: that it decodes the bytes in the passed string using the fromAscii() function, which — despite its name — uses the codec returned by QTextCodec::codecForCStrings(), or Latin-1 if you didn't set one. Thus, if you pass UTF-8 data to it without doing anything else, QString is NOT going to decode your data properly.
Note also the codec set is application-wide — once you set it, you change the behaviour of fromAscii() in your code, in libraries you are using, in plugins you may have loaded, etc. If they're very poorly coded you may even break them by doing so (BT;DT).
So what should I use instead?
There are a number of available options:
- Switch all of your code editors to use UTF-8, convert all of your codebase (f.i. by using the iconv(1) tool), set your compiler input and execution charsets to UTF-8, then in your code use QString::fromUtf8(), trUtf8(), etc.; this way, will do the right thing™.
QString str = QStringLiteral("ßàéöø")
- If your source must be 7-bit ASCII, you can still make use of QString::fromUtf8 by either using the u prefix, or performing the encoding by hand and using the escape sequence. Be sure that your execution charset is UTF-8 (or that string literals pass through unchanged). For instance,
QString str = QString::fromUtf8("3\xb7"); // str is "÷"
- If your source is Latin-1 and you don't want to risk it to break if someone changes the codecForCStrings(), you can use the static method QString::fromLatin1().
- QLatin1String (which is thin wrapper around a Latin-1 encoded char *) can also be handy.
Should I use tr() / trUtf8() even if I don't plan to translate my application?
Yes. For instance, you do want to handle plural forms correctly, and not to reinvent the wheel by doing it by hand.
A small digression — what's an encoding?
In information theory, a code is nothing more than a rule — a function — to translate a discrete piece of information (usually, symbols from a source alphabet) into another format of representation (symbols or sequence of symbols of a target alphabet).
The process of converting a symbol from the source alphabet into its associated sequence of symbols of the target alphabet is called encoding; the opposite process is called decoding. We can naturally extend the encoding and the decoding definitions to sequence of symbols of the source alphabet (that is, a string of the source alphabet) into the corresponding sequence made of (sequence of) symbols of the target alphabet.
For instance, a very famous code is the Morse code, which translates letters in the Roman alphabet, Arabic numerals (digits) and some punctuation characters into sequences of dots and dashes.
| Symbol | Morse encoding |
|---|---|
| A | .— |
| B | — . . . |
| 9 | — — — — . |
There are a certain number of properties that we'd like a code to have: its rule must be an injection, because we don't want to map two different pieces of information into the same representation (we wouldn't know how to translate it back); it should not be unnecessarily verbose ; it could add some error detection and/or error correction schemes ; etc.
A character encoding is no different: it's a rule to translate symbols from (usually) a human alphabet into sequences of bits or bytes[3]. The most famous character encoding is probably US-ASCII, which maps Roman letters, Arabic numerals, punctuation and some control characters to the numbers in the range 0—127, and thus, requiring 7 bits in binary.
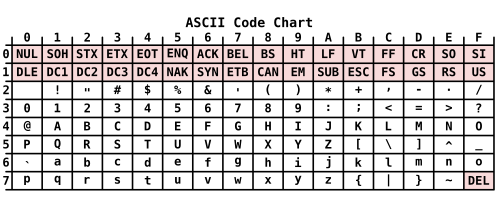
Usually an ASCII-encoded character is encoded in a full byte with the most significant bit is set to 0, thus allowing us to index symbols in a ASCII-encoded string by simply indexing bytes.[4]
As you may have guessed, US-ASCII is not suitable for anything but American English — it lacks all additional characters needed to deal with other languages. The ISO/IEC 8859 series of standards extended US-ASCII by encoding additional 128 symbols with the numbers in the range 128—255, that is, using the other half of values available inside a byte.
Many other encodings exist out there , and writing down a comprehensive list of them is almost impossible. Moreover, anyone can invent his own encoding for an arbitrary set of symbols. This has simply led to many problems when a piece of software had to deal with multiple writing systems (for instance, any browser).
Enter Unicode
Unicode is a industry standard that tries to cover as many writing systems as possible in a unified manner, not only in terms of supported symbols, but also in terms of rules for character normalization, character decompositiion, string collation (i.e. ordering), bidirectional writing, and so on.
All the symbols inside the Unicode standard are called the the Universal Character Set (UCS) and they are defined by the ISO/IEC 10646 standard. Every symbol has a number in the range from 0x000000 to 0x10FFFF[5], which is called a code point; the standard notation for naming Unicode code points is U+XXXX (where XXXX are hex digits).
What's so great about Unicode is that you can stop caring about all the details of the various writing systems. Just use a Unicode-compliant library and let it do all the harsh work for you. All in all
Unicode encodings
A code point is still a virtual entity; it's not an encoding. The Unicode standard defines several standard encodings for code points.
Notes
- ↑ You don't. Disable those constructors by defining QT_NO_CAST_FROM_ASCII and QT_NO_CAST_TO_ASCII in your codebase.
- ↑ This whole story isn't 100% accurate — as Thiago Macieira kindly pointed out in his blog entry , if you don't specify any encoding option GCC actually outputs the same bytes it read from the source file.
- ↑ … or octets, but for brevity's sake let's just assume that a byte is always 8 bits.
- ↑ Other uses have been suggested for the remaining bit in a byte, for instance parity check.
- ↑ Not all numbers in the range are used, though.